Recursive Company Retreat 2025 in Chiba
In April 2025, the Recursive team, now 48 members strong, gathered in Chiba, Japan, for a three-day company retreat. The goal? To strengthen team bonds, deepen personal connections, and align around our shared values and vision for the future.

%20(1).jpg)
%20(1).jpg)
.jpg)

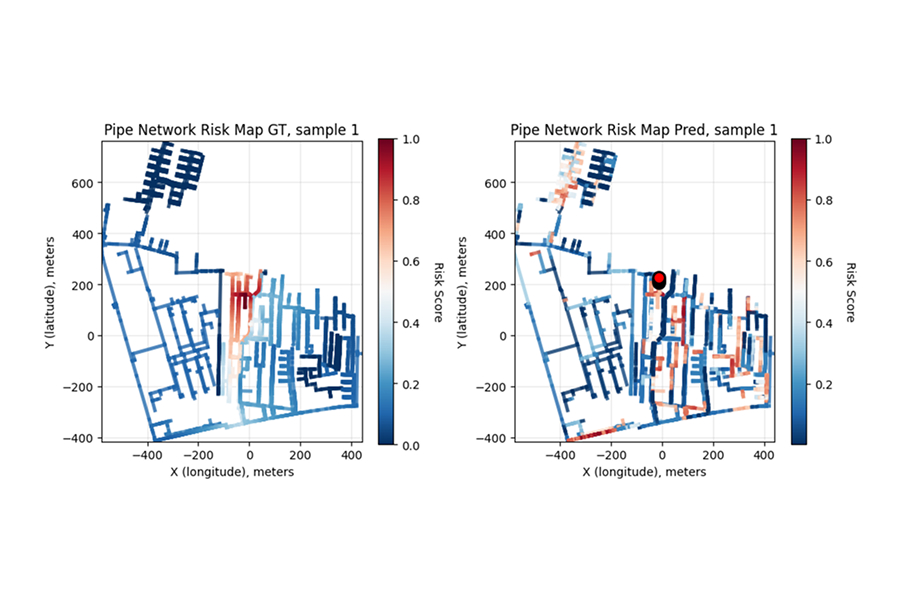
.jpg)

.jpg)



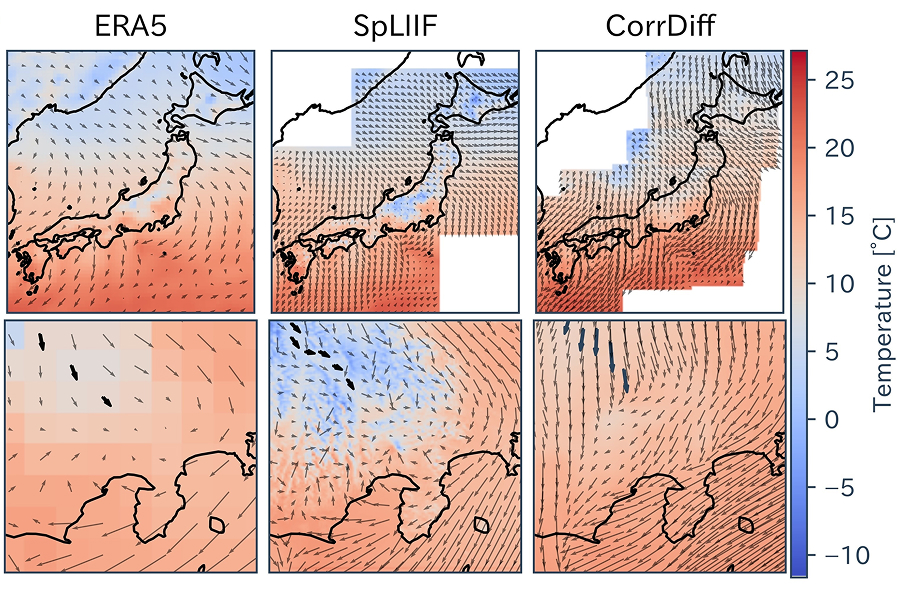


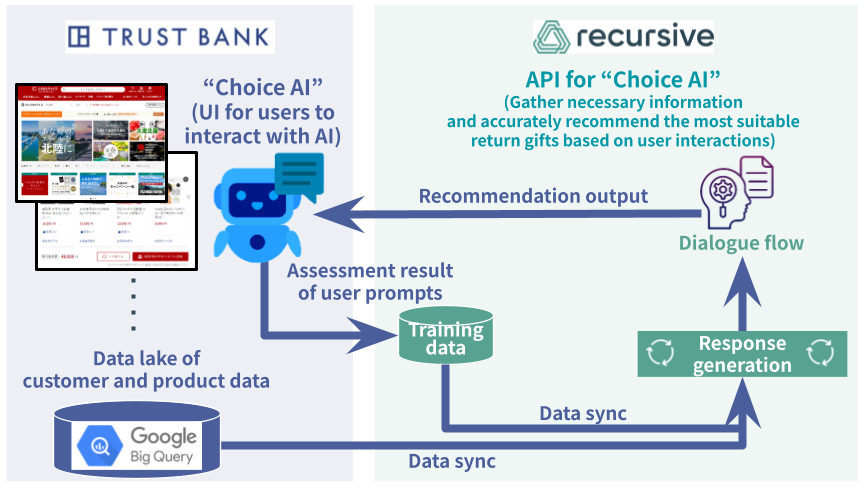

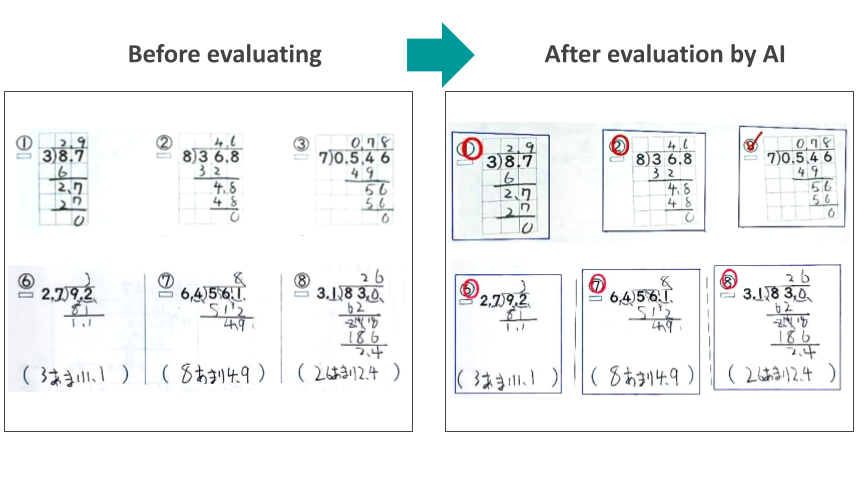












.jpg)




.jpg)




















%20(1)%20(1).png)

































.png)




















