
At Recursive, we are committed to delivering cutting-edge AI solutions, and today, we are excited to share the results of our extensive evaluation of open-source LLM models. As more businesses embrace open-source technologies for their transparency and customizability, one key question remains: Can these models match the performance of closed-source alternatives like GPT-4?
To address this, we used our recently launched Flow Benchmark Tools to thoroughly test the performance of leading open-source models by integrating them into FindFlow, a platform developed by Recursive for text generation, search, and analysis.
The tests focused on assessing two critical functions: question answering using retrieval-augmented generation (RAG) and whole document understanding. These capabilities form the core of our FindFlow platform as SearchAI and AnalysisAI features.
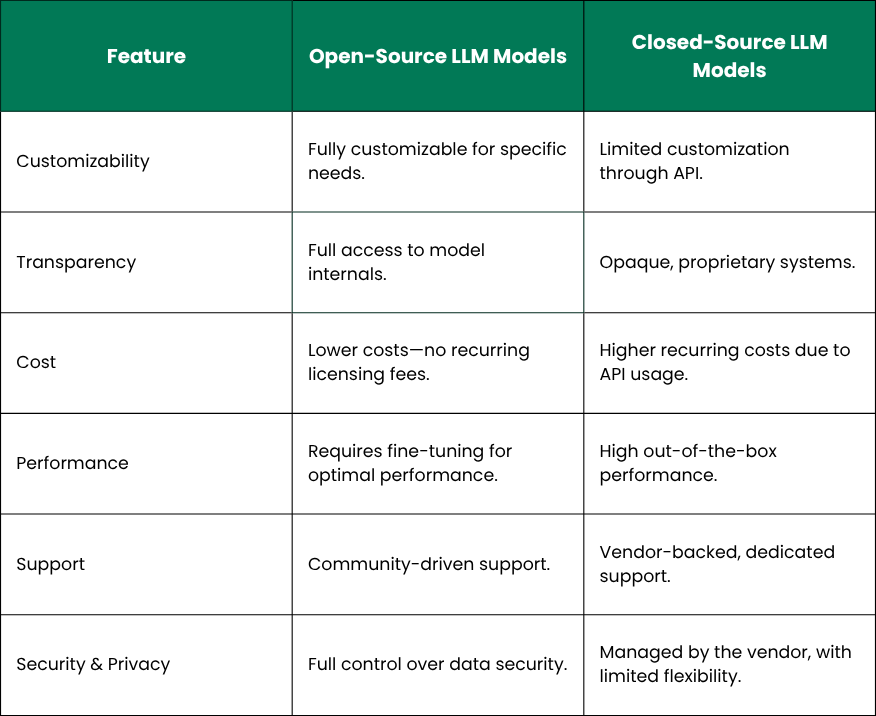
Open-source LLMs are publicly accessible models whose code, architecture, and sometimes training data are made available for use, modification, and redistribution. Businesses can leverage these models for their own applications, taking advantage of three key benefits:
To provide accurate and actionable insights, we used Recursive’s proprietary Flow Benchmark Tools to test SearchAI and AnalysisAI features of FindFlow on several open-source LLM models provided by top companies such as Google, Microsoft, Meta, and others.
A unique feature of our tools is the multilingual capability, allowing us to evaluate model performance not only in English but also in other languages, with a specific focus on Japanese. This multi-language assessment makes our benchmarks particularly relevant for global applications.
The approach used in the Flow Benchmark Tools mirrors real-world use cases by utilizing a dataset of Japanese government documents with challenging questions to ensure a thorough evaluation. It employs a multi-model approach, including state-of-the-art models such as GPT-4, Claude 3, and Gemini, to generate objective results, with ratings from 0 (worst) to 10 (perfect). For more details, check out our launch announcement article.
Our Flow Benchmark Tools are publicly available on GitHub and PyPi.
It’s essential to analyze open-source LLM models by size, as performance varies significantly between big, medium, and small models. Larger models generally deliver superior accuracy, especially in complex tasks, while smaller models offer a cost-efficient solution, capable of running on personal computers with lower hardware requirements.
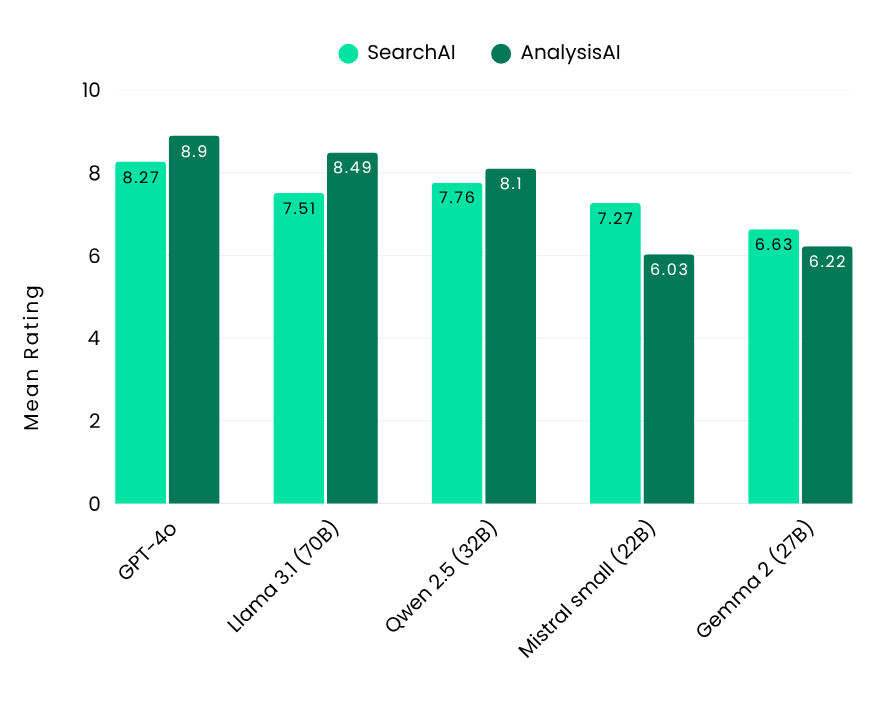
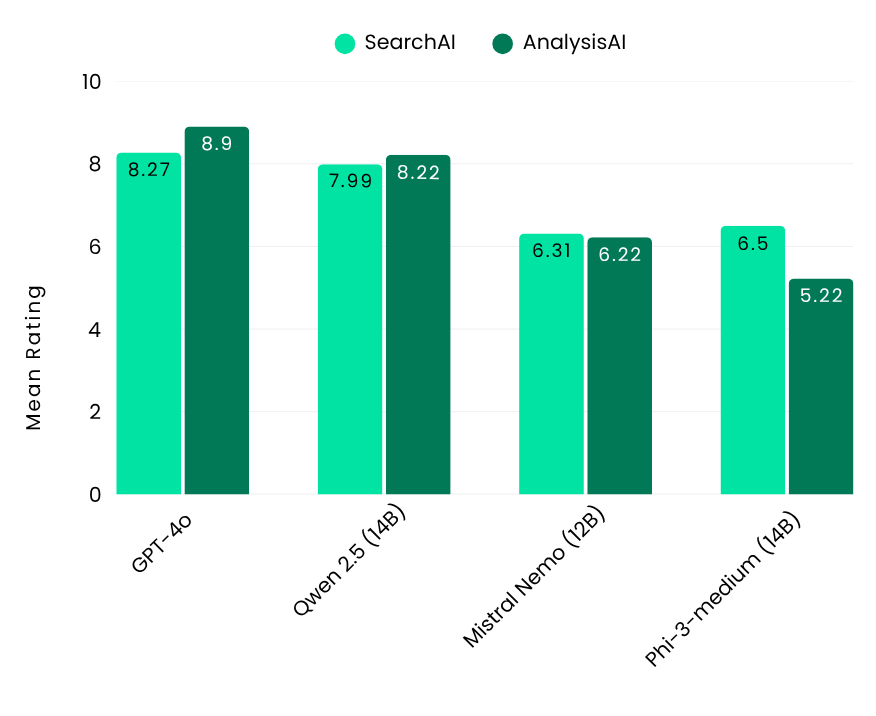
To establish a performance benchmark, we included GPT-4o, a closed-source model renowned for its strong capabilities. When integrated with FindFlow, it achieved impressive scores of 8.27 for SearchAI and 8.9 for AnalysisAI.
.png)
Our Flow Benchmark results showcased the top-performing open-source LLM models across three size categories. For big-size models, Llama 3.1-70B (Meta) and Qwen 2.5-32B (Alibaba) excelled in both SearchAI and AnalysisAI. In the medium category, Qwen 2.5-14B (Alibaba) stood out, particularly for its multilingual strengths, performing well in both English and Japanese. Among small models, GLM4-9B (Zhipu AI) impressed by outperforming larger models in accuracy and efficiency.
These findings show that with the right integration open-source LLMs can achieve performance on par with closed-source models while providing greater flexibility and cost savings.
To discover how FindFlow can save your business 20+ hours a month and guide you in selecting the best platform, reach out to us at sbdm@recursiveai.co.jp.
Founded by a former senior research engineer at Google DeepMind, Recursive brings together world-class talent from across disciplines to engineer results where others can't.






