The Machine Learning Engineer (MLE) role at Recursive
RecursiveAI2023-11-16

In this article, we provide a description of some of the key responsibilities of our MLEs, and a brief overview of some of the problems that our Machine Learning Engineers solve on a daily basis.
The key responsibilities of a Machine Learning Engineer
In most projects, some of the key responsibilities of our MLEs are:
- Conducting comprehensive data collection, often involving literature and dataset reviews to assess dataset availability and data collection methodologies.
- Employing data visualization and analysis techniques to extract meaningful insights from the collected data.
- Engaging in data engineering tasks, which often requires deepening your understanding of the problem, and analyzing the data in different lights.
- Developing machine learning or deep learning models, a process that typically encompasses literature reviews, the formulation of modeling proposals, technical discussions with the team, model training, inference runs, and result evaluations.
- Collaborating closely with our project managers to gain a comprehensive understanding of the client's needs and devising a strategy for a successful project delivery.
- Thoroughly documenting your work and sharing your findings with the team.
While the list provided is extensive, it does not encompass all the aspects of being a Machine Learning Engineer at Recursive. The role is dynamic and multifaceted, with each project having its distinct requirements and challenges.
What Machine Learning Engineers do at Recursive
Recursive collaborates directly with corporations who present us with challenges that can be addressed through data science, machine learning, deep learning, software engineering, or a combination of these fields. In addition to our client projects, we actively maintain and enhance our own products, such as FindFlow (https://www.findflow.ai/) and Borealis (https://borealis.jp/).
At Recursive, Machine Learning Engineers are integral to every data-related aspect of solving our clients' problems, encompassing data collection, data engineering, analysis, AI modeling, and model deployment.
Our MLEs have engaged in diverse projects, including developing product recommendation systems, forecasting from time series data, generating images and videos using generative AI, and tackling natural language processing challenges.
Groundwater level prediction
Problem description
We have joined forces with IHI and Sumitomo Forestry to leverage machine learning for the forecasting of groundwater levels in a forest in West Kalimantan. The prediction of groundwater level holds significant importance as it informs the formulation of fire prevention strategies. This is especially pertinent in the Indonesian region in question, where the forests contain abundant peat deposits deep underground, which are rich in carbon content and are highly flammable, making fire management in these peatlands an arduous task, and emphasizing the critical role of fire prevention and groundwater level management in that area.
Our client currently manages groundwater level through the irrigation and drainage of specific zones, primarily relying on sensor-generated groundwater level measurements collected throughout the forest. However, there is a distinct advantage in transitioning to a predictive groundwater level management approach, and in expanding the groundwater level measurements and predictions to cover the whole terrain of the forest, instead of being limited to specific groundwater level sensor locations. The motivation to achieve that was the driving force behind our collaboration with IHI and Sumitomo Forestry. In particular, our MLEs had the goal of delivering a method to provide groundwater level predictions with high spatial and temporal resolution up to 7 days in the future for arbitrary locations within the region of interest.
In the scope of this project, our clients have supplied a diverse dataset specific to the West Kalimantan region, spanning several years. This dataset encompasses various information, including groundwater level measurements, precipitation records at select locations within the region of interest, manually recorded elevation data, the geospatial distribution of canals used for irrigation and water table control, as well as the water levels within these canals.
The traditional solution
The traditional approach to solving this problem would be to define a physical model of the region, which involves a detailed description of physical properties of the region at a high spatial and temporal resolution (e.g. topography, peat depth, weather conditions, hydraulic coefficients), as well as a precise definition of the physical equations that govern the subsurface water flow in a simulator. Such approach, when successful, tends to have a high predictive accuracy. However, the main challenges with defining a physical model are:
- Data collection for physical modeling is resource intensive, but it is crucial. If the physical properties are not precisely described at high resolutions, the model accuracy cannot be guaranteed.
- A physical model is specific to a single region, and it cannot be generalized to other regions.
Given these challenges, the cost of data collection, and our client’s expectation to quickly apply one solution to different regions in the future without a lot of additional effort, we have proposed to tackle this challenge in a more data-driven manner.
Our solution and the work done by our MLEs
Our MLEs have worked with leveraging the data collected by IHI and Sumitomo Forestry with machine learning methods.
The first steps of the project involved careful investigation and analysis on the provided data. By collaborating with the client, our MLEs built a deep understanding of the data and the problem, which was crucial for them to proceed with:
- Developing methods to clean and process different types of data (e.g. determining the best method to deal with missing values and outliers).
- Developing methods to combine data collected at different frequencies.
By building on these steps, they then successfully applied different machine learning models to make predictions on the sensor locations.
However, due to the sparse nature of the data, both temporally and spatially, and the presence of noisy measurements, developing data-only methods, by either adapting our machine learning methods or developing deep learning models, to extend the groundwater level predictions to the whole region of interest would not be the best approach.
Instead of relying solely on data, our MLEs developed a unique fusion of machine learning and physics-based modeling. By including physics-based priors to a machine learning model, our MLEs managed to overcome the challenge of working with a small dataset, and they empowered our client to forecast groundwater levels for the entire specified area, up to seven days in advance, as depicted in the image below.
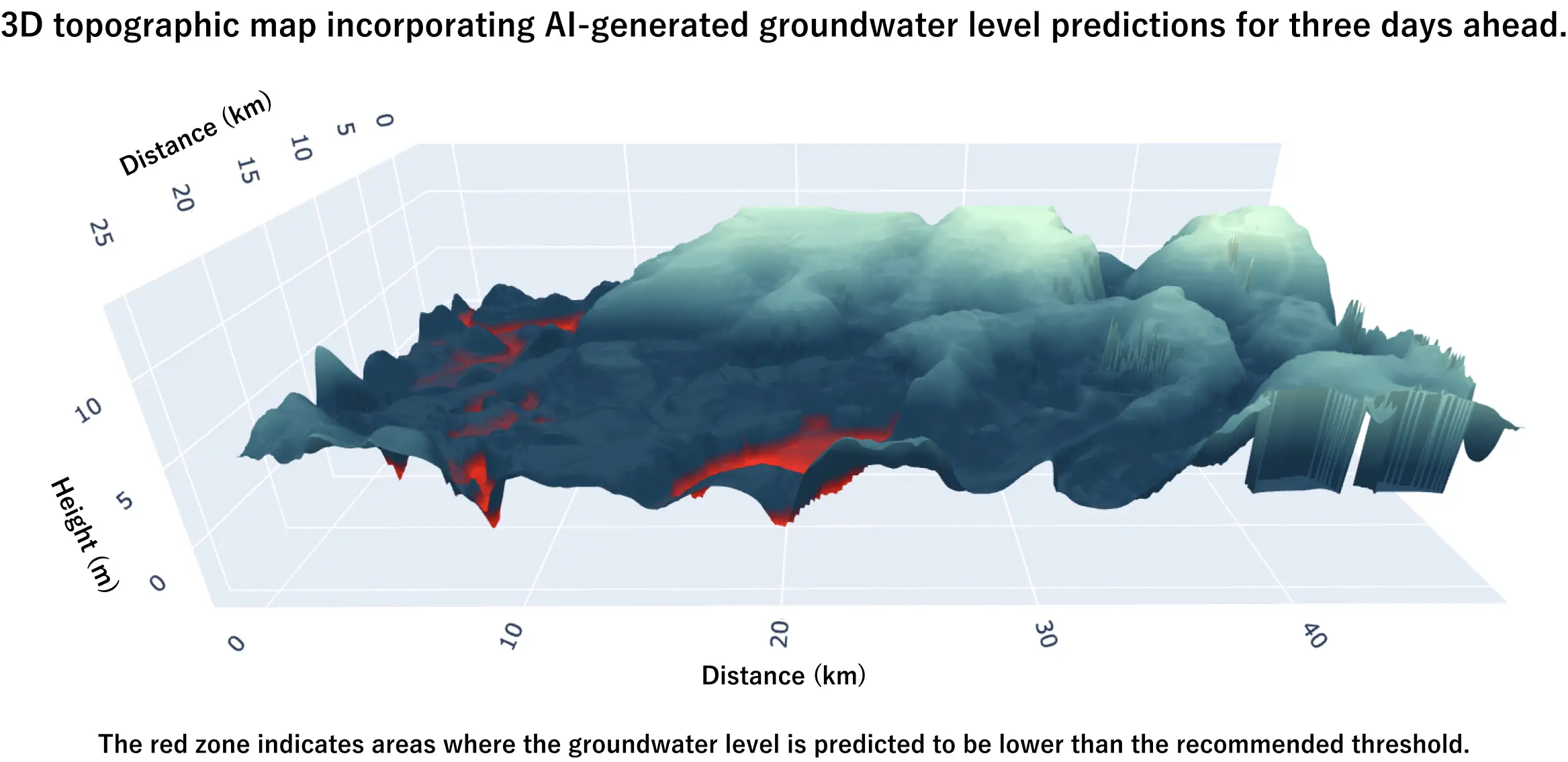
Why our solution is better than existing solutions
The advantages of combining physical priors and machine learning compared to data-only approaches are:
- Physical priors enhance data-based predictions, specially when the data is noisy.
- Physical priors are specially helpful to guide the predictions where there are no sensors. They can help our model make reasonable guesses.
- The addition of physical priors encourage the model’s predictions to be in accordance to the laws of physics.
The advantages of our fusion approach compared to the traditional physical modeling approach are:
- It is not required to have a detailed and high-resolution specification of the physical characteristics of the region of interest to apply our model.
- The fusion approach developed by our MLEs can be applied to other regions without additional modeling.
Borealis
Problem description
To make informed decisions, having access to historical weather data at a high spatial resolution is crucial. For instance, when deciding the optimal locations for solar panel installation, it's essential to consider factors like the amount of solar radiation received in a specific area, often measured within a few square kilometers for industrial purposes. Additionally, understanding weather-related variables is critical for identifying regions susceptible to certain disasters, such as wildfires, and taking preventive measures.
Today, we are fortunate to have access to vast amounts of data. The Japan Meteorological Agency (JMA), for instance, has collected decades' worth of weather data, including information on solar radiation, precipitation, temperature, and more, from weather stations across Japan and through satellites and other sensors. This data allows us to trace the historical weather conditions at these sensor locations. However, the challenge we at Recursive aimed to address with Borealis was extending this historical data to cover the entire Japanese territory at a high spatial resolution.
Our solution and the work done by our MLEs
Borealis (https://borealis.jp/) is our exclusive AI-powered product—an advanced dashboard empowering users to visualize various weather parameters (e.g., solar radiation, rainfall, temperature) across Japan in high-resolution maps. These maps are constructed using 20 years' worth of data gathered from weather stations distributed across the country. A concise overview of Borealis is provided in the diagram below.
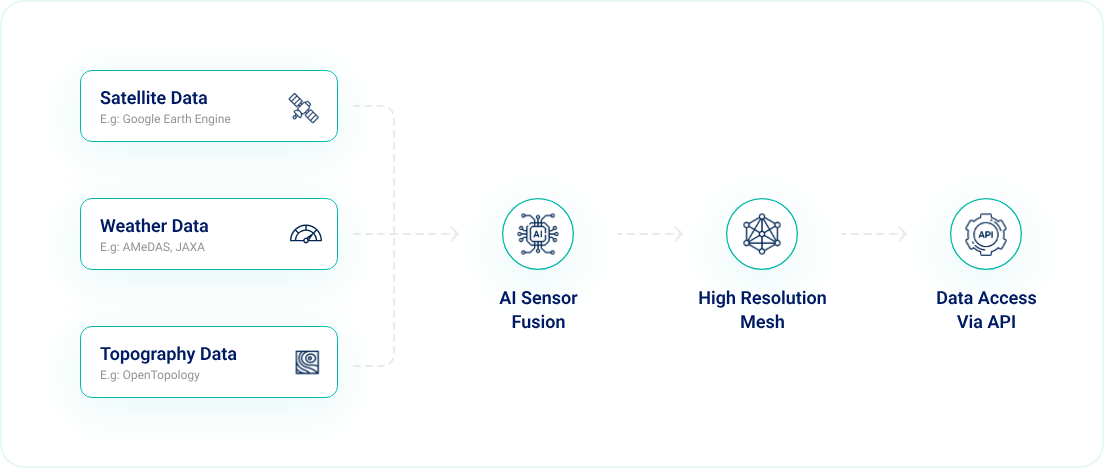
Our AI model harnesses the combined capabilities of satellite, weather, and topographical data to extrapolate sparse weather measurements in Japan into high-detail weather maps with a remarkable 100-meter resolution.
To accomplish that, our Machine Learning Engineers (MLEs) undertook the following tasks:
- Conducted comprehensive data collection from various sources, involving extensive research on potential datasets and, when necessary, the development of code for data retrieval.
- Processed and analyzed the acquired data, which included cleaning and handling missing values.
- Devised techniques to align data obtained at different times and locations effectively.
- Researched and developed a deep learning approach to generate a high-resolution mesh from the sparse data points, covering the entire Japanese territory.
- Together with our Software Engineers, enhanced the data and model pipeline, ensuring it could operate efficiently in production via API access.
In the ongoing development of this product, our Machine Learning Engineers continue to collaborate closely with our Software Engineers. Together, they address various challenges, including data collection from diverse sources, data preprocessing, optimization of model inference speed to enhance user experience, and the integration of physical priors into the AI models. As the project evolves, new challenges may arise, and our team remains dedicated to overcoming them to further enhance Borealis.
Why our solution is better than existing solutions
Borealis offers several key benefits:
- Exceptional Map Resolution: Our generated maps boast significantly higher resolutions than those of the majority of our competitors.
- Utilizing Decades of Reliable Data: Borealis leverages extensive datasets accumulated over decades from reputable and trusted institutions.
- Empowering Sustainability Decision Makers: Borealis is dedicated to equipping decision makers with invaluable insights for their sustainability-driven initiatives.
Author

Machine Learning Engineer
Mariana Makiuchi
Mariana graduated from the Master’s program at Tokyo Institute of Technology in the Major of Artificial Intelligence. During that time, she was supported by the MEXT scholarship acquired through the Japanese Embassy recommendation. Previous to enrolling in the Master’s program, Mariana graduated with honors from the University of Brasilia after concluding the Mechatronics Engineering undergraduate program. During her time as an undergraduate and graduate student, Mariana had the opportunity to participate in AI research, and she published two papers in domestic conferences, one journal, and 4 papers in international conferences, of which she presented 3.
![Cover image for [Event Report] Recursive Company Retreat 2025 in Chiba](/content/images/image_9369b7f0ad8633e62c48c9b14f2606f8.jpg)


