
Today, we're proud to present the Flow Benchmark Tools, designed to complement and strengthen our FindFlow platform. This open-source release marks a significant milestone in our commitment to advancing retrieval-augmented generation (RAG) technology and empowering the global AI community.
The Flow Benchmark Tools represent a major leap forward in our ability to evaluate and optimize RAG systems. As an extension of our FindFlow suite of platforms, these tools address a critical need in the AI landscape: providing a standardized, comprehensive method for benchmarking RAG pipelines.
Our goals for the Flow Benchmark Tools are ambitious yet focused:
Before diving into the specifics of our benchmarking tools, it's crucial to understand the technologies they're designed to evaluate. Large Language Models (LLMs) are the backbone of modern AI systems, leveraging vast neural networks to understand and generate human-like text. These models, measured by the number of parameters they contain, excel at capturing the general patterns of language use.
However, LLMs have limitations when it comes to accessing current or highly specific information. This is where Retrieval-Augmented Generation (RAG) comes into play. RAG is a powerful technique that enhances the capabilities of LLMs by incorporating external knowledge sources. It allows AI systems to combine the fluency and reasoning capabilities of LLMs with up-to-date, factual information retrieved from external databases.
The importance of RAG cannot be overstated. It enables a wide range of use cases where accuracy and reliability are paramount. In customer support, RAG ensures that AI assistants provide accurate, up-to-date information about products, services, and policies, leading to improved customer satisfaction and reduced workload for human agents. The education sector benefits greatly from RAG, as it allows educational AI tools to access and present the most current knowledge in various fields of study, keeping learners at the forefront of their disciplines. In the realm of industrial and academic research, RAG empowers researchers with AI assistants that can draw upon vast libraries of scientific literature and data, accelerating the pace of discovery and innovation. Content creators also find immense value in RAG systems, which help them by providing accurate, factual information to support their work, enhancing the quality and credibility of their output.
By combining the strengths of LLMs with external knowledge retrieval, RAG significantly reduces the risk of AI hallucinations – instances where models generate plausible but incorrect information. This makes RAG-enhanced systems more trustworthy and applicable in critical domains where factual accuracy is essential.
The Flow Benchmark Tools offer unparalleled insights into RAG system performance. By addressing the complexities inherent in RAG pipelines—including semantic retrieval, query generation, and LLM-based answer generation—our tools provide a nuanced, comprehensive evaluation framework.
While there are numerous LLM benchmarks available in the field, such as LMSYS's Chatbot Arena and Arena-Hard, SEAL Leaderboards, and ChatRAG-Bench, the Flow Benchmark Tools stand out for their unique approach. Unlike most benchmarks that focus on general queries or pre-processed documents, our tools emphasize document-specific information retrieval and end-to-end document processing. This approach more closely mirrors real-world scenarios, making our benchmarks more product and end-user focused.
By evaluating the entire pipeline from raw document processing to information retrieval and response generation, the Flow Benchmark Tools provide a more holistic and practical assessment of RAG system performance. This comprehensive approach aligns with our goal of developing RAG technologies that excel not just in controlled environments, but in the complex, document-rich scenarios that businesses and researchers encounter daily.
We're especially proud to announce that our initial release focuses on Japanese language performance, setting a new benchmark for non-English RAG systems. This emphasis on multilingual capability reflects our commitment to developing AI technologies that serve a global audience.
In conjunction with this release, we're sharing benchmark numbers that compare FindFlow's performance against several leading RAG systems. These results demonstrate the power and versatility of our approach, while also providing valuable data to the wider AI community.
By open-sourcing the Flow Benchmark Tools, we're inviting the global AI community to join us in advancing RAG technology. We believe that collaboration and transparency are key to unlocking the full potential of AI, and we're excited to see how developers, researchers, and companies will leverage and build upon our work.
Our release of the Flow Benchmark Tools is just the beginning. We're committed to continually improving and expanding these tools, with plans to incorporate additional languages, extend our benchmarking capabilities, and refine our methodologies based on community feedback.
We can't wait to see how the AI community will use the Flow Benchmark Tools to drive innovation, improve RAG systems, and ultimately create more powerful, accurate, and reliable AI applications. We look forward to your feedback and contributions as we work together to shape the future of AI technology.
Our Flow Benchmark Tools are now publicly available on Github and PyPi.
We're excited to share the results of our comprehensive benchmarking efforts, which highlight FindFlow's exceptional performance in two critical areas: Question Answering using RAG (Retrieval-Augmented Generation) and Whole Document Understanding. These benchmarks not only showcase the capabilities of our SearchAI and AnalysisAI pipelines but also demonstrate how FindFlow stands out in the competitive landscape of AI-powered document analysis tools.
Our benchmarking process was designed to be thorough, fair, and reflective of real-world scenarios. We used a dataset of Japanese government documents paired with challenging questions, which we plan to open-source soon to contribute to the wider AI research community. To ensure the most objective and robust evaluation possible, we employed an automated evaluation system that leverages multiple state-of-the-art LLMs, including GPT-4, Claude 3, and Gemini. This multi-model approach allows us to mitigate potential biases and provide a comprehensive assessment of performance. The evaluation system outputs a mean opinion rating with values ranging from 0 (worst) to 10 (perfect).
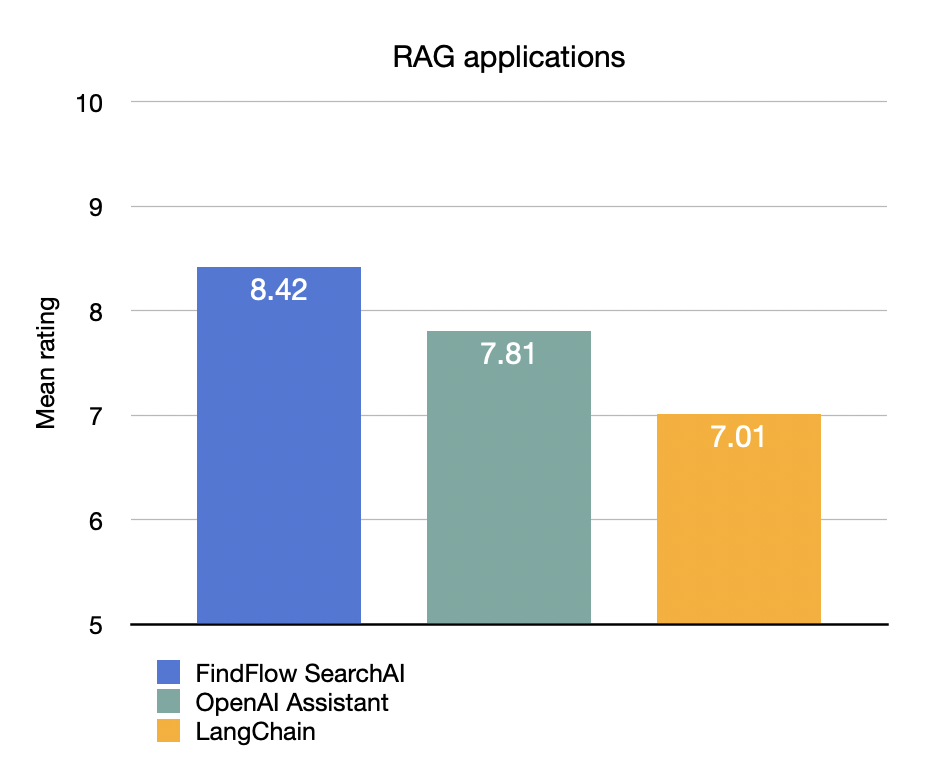
In the realm of RAG question answering, our FindFlow SearchAI pipeline was put to the test against two popular question answering pipelines: OpenAI Assistant and the default LangChain RAG pipeline. The results speak for themselves:
These scores clearly demonstrate FindFlow SearchAI's superior performance, outpacing the nearest competitor by a significant margin of 0.61 points and the third-place solution by 1.41 points.
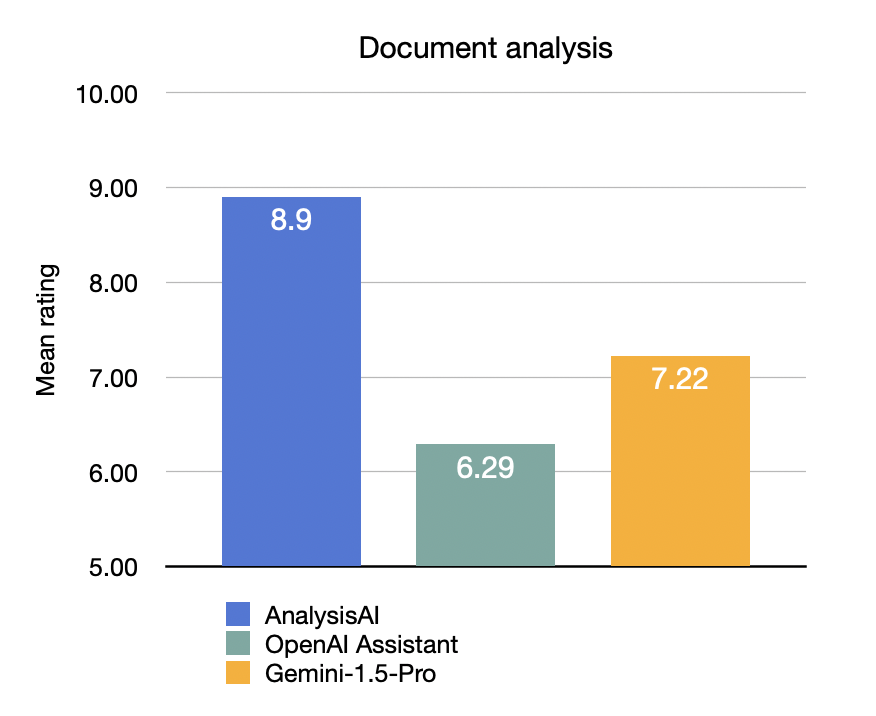
For whole document understanding, we benchmarked our FindFlow AnalysisAI against OpenAI Assistant and Gemini's long-context LLM (Gemini-1.5-Pro). The results once again highlight FindFlow's capabilities:
In this category, FindFlow AnalysisAI's performance surpasses the runner-up by 1.68 points and the third-place contender by a substantial 2.61 points.
As we continue to refine and enhance our technology, we remain dedicated to maintaining this high standard of performance and to providing our users with the most advanced, reliable, and effective document analysis tools available in the market.
Founded by a former senior research engineer at Google DeepMind, Recursive brings together world-class talent from across disciplines to engineer results where others can't.






