
The rapid adoption of generative AI is transforming industries worldwide. According to McKinsey's 2024 report, AI adoption has surged to 72% of organizations, with 65% of respondents reporting regular use of generative AI in at least one business function.
This rapid growth emphasizes the need for cost-efficient, customizable, and privacy-focused solutions like small-size open-source large language models (LLMs). However, as highlighted in our benchmark test results, these models often fall short in performance compared to their larger counterparts. To address this, we explored fine-tuning and prompt optimization as strategies to close the gap.
Small open-source LLMs are publicly accessible AI models with fewer parameters (under 10B), making them deployable on standard hardware such as consumer-grade PCs. Their accessibility makes them an attractive option for organizations and individuals with limited technical resources.
In this article, we focus on optimizing three popular small open-source models: Qwen 2.5-7B (Alibaba), Llama 3.1-8B, and Llama 3.2-3B (Meta).
We assessed the models using Recursive’s proprietary Flow Benchmark Tools, designed to evaluate models on real-world tasks. The benchmark utilized a dataset of Japanese government documents paired with challenging questions to test two critical capabilities:
Flow Benchmark Tools evaluated model performance across English and Japanese, using a scoring system from 0 (worst) to 10 (perfect).
Prompt optimization involves refining how instructions or input text are presented to an AI model. Think of it as crafting a clear, well-structured directive to guide the model’s response. This low-cost strategy is often the first step to improving performance without altering the model itself.
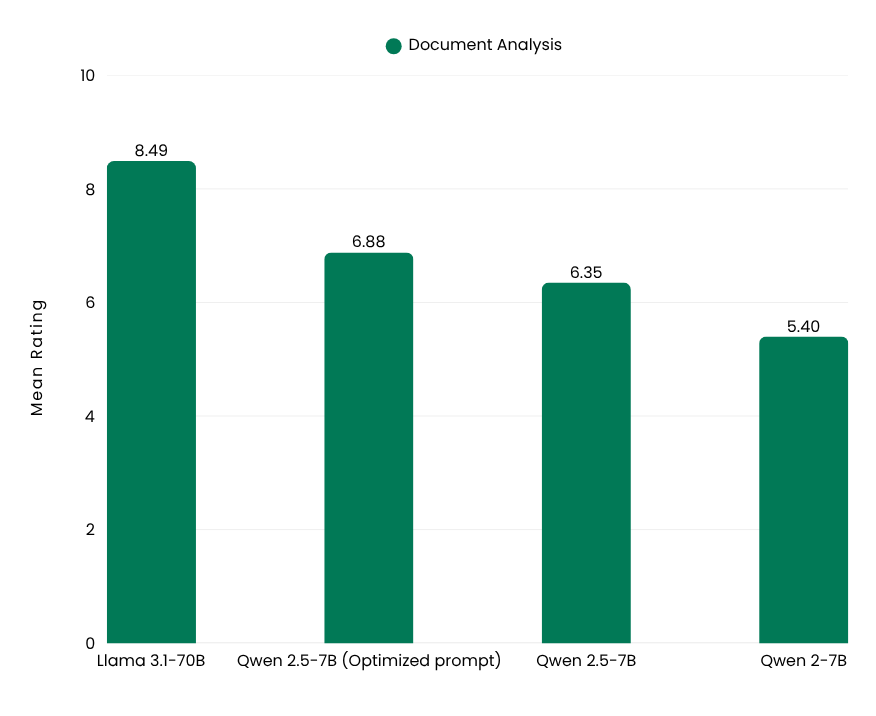
In our experiments, the optimizations were focused on document analysis, as question-answering with RAG relies more heavily on retrieval quality, which is less influenced by prompt adjustments.
The position of the query within the prompt significantly influenced results. For example, placing the query after the document block for the Qwen 2.5-7B model improved its score from 6.35 to 6.88. This demonstrates the value of careful prompt design in enhancing performance.
Hallucinations occur when AI models generate incorrect or fabricated answers with confidence. For example, a model might invent URLs that do not exist or provide information absent from the input data. This issue is particularly problematic for tasks requiring factual accuracy, such as document analysis.
In our tests with Llama 3.1-8B, minor prompt adjustments were insufficient to mitigate hallucinations. However, using a structured data prompt—adapted from DSPy—significantly reduced hallucinations, improving the model’s performance score from 4 to 8. This template defines clear input fields and enforces strict output formats, ensuring the model produces accurate and consistent responses.
Structured data prompt template (adapted from DSPy):

Fine-tuning adapts pre-trained AI models by further training them on a specialized dataset aligned with specific tasks. Using LoRA (Low-Rank Adaptation), we efficiently trained the models by adding small, trainable modules to existing layers, which adjust weights without changing the original parameters, reducing memory usage and speeding up training.
To align the models with our benchmark tasks, we created a dataset modeled on the Flow Benchmark instruction style. Fine-tuning was applied to two models, Llama 3.1-8B and Llama 3.2-3B, and produced mixed results depending on the task.
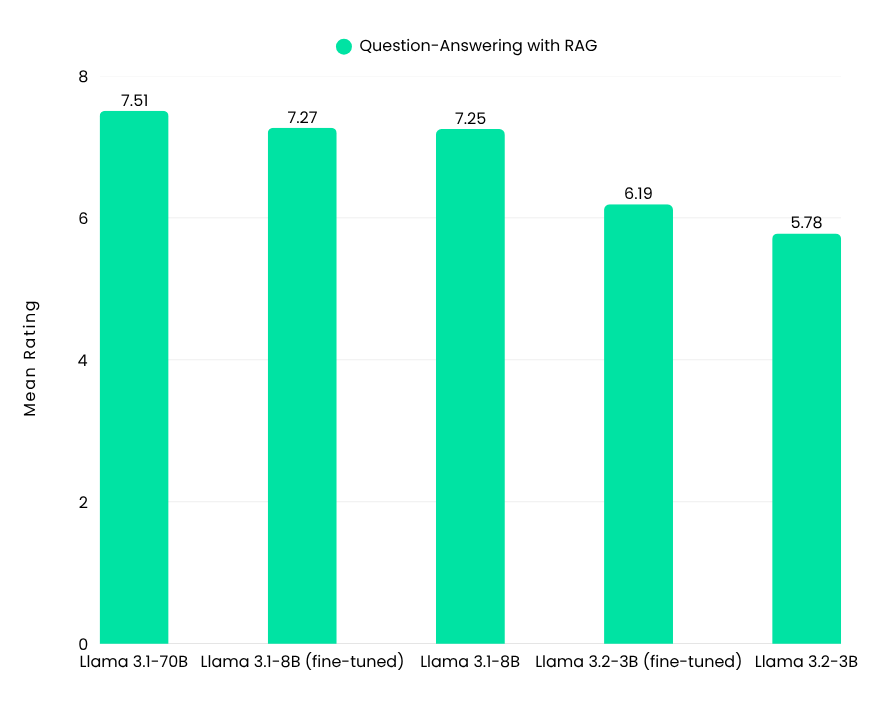
The limited improvement stems from the task’s reliance on information retrieval—a capability the models already handled well. Fine-tuning focused more on helping the models follow task-specific instructions than introducing new knowledge. Since the Llama 3.1-8B model’s performance was already comparable to larger models like Llama 3.1-70B, further fine-tuning provided minimal additional benefits.
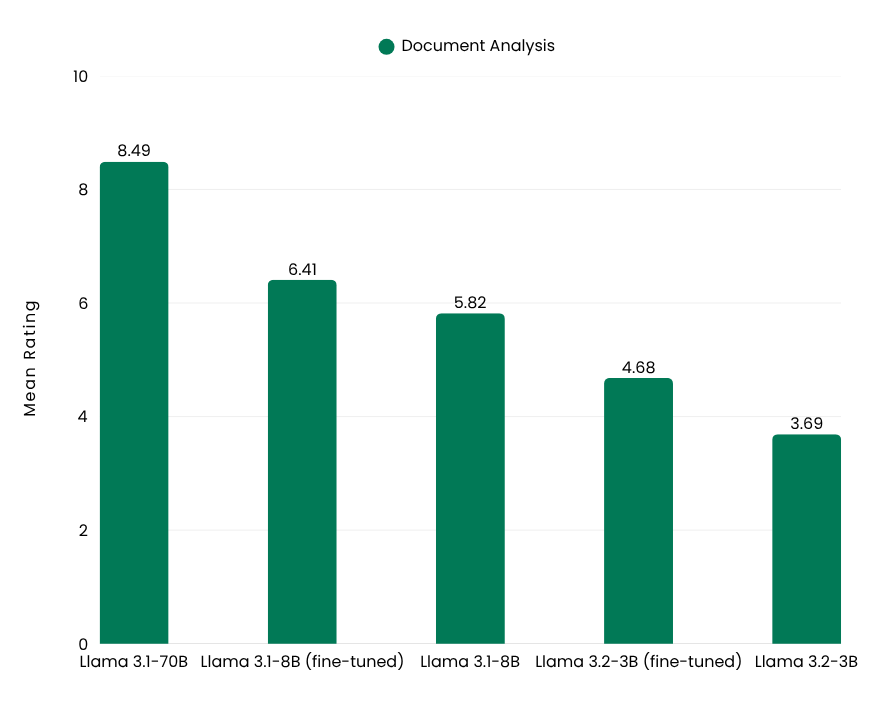
These significant improvements resulted from the fine-tuning process, which enhanced the models’ ability to understand and adapt to document analysis tasks, leading to higher scores.
The results presented in this article highlight the importance of fine-tuning and prompt optimization in maximizing the potential of small open-source LLMs:
By combining these techniques, small open-source models can narrow the performance gap with larger alternatives while maintaining advantages in cost, customization, and privacy.
At Recursive, our commitment to open-source technologies reflects our vision of democratizing AI while empowering enterprises to build fairer, more sustainable solutions. Reach out to us at sbdm@recursiveai.co.jp to discuss how our tools can enhance your AI strategy.
Founded by a former senior research engineer at Google DeepMind, Recursive brings together world-class talent from across disciplines to engineer results where others can't.






