.jpg)
Recursiveは、最先端のAIソリューションを提供することにに尽力しており、この度、オープンソースLLMモデルの包括的な評価結果をお届けできることを嬉しく思います。多くの企業が、透明性とカスタマイズ性の高さからオープンソース技術を採用する中、これらのモデルがGPT-4のようなクローズドソースの代替モデルと同等の性能を発揮できるのかという重要な疑問が残ります。
この疑問に答えるため、当社は最近公開したFlow Benchmark Toolを用いて、Recursiveが開発したテキスト生成、検索、および分析プラットフォームであるFindFlowに主要なオープンソースモデルを統合し、性能を徹底的に検証しました。
このテストでは、RAG(検索拡張生成)を用いた質問応答と、文書全体に対する理解という2つの重要な機能に焦点を当てました。これらの機能は、FindFlowのSearch AIとAnalysis AI機能の中心的な役割を果たしています。
オープンソースLLMは、コード、アーキテクチャ、時にはトレーニングデータが公開されており、利用や変更、再配布が可能なモデルです。企業はこれらのモデルを活用することで、以下の3つの利点を得ることができます:
.png)
Recursiveは独自のFlow Benchmark Toolsを用いて、FindFlowのSearchAIやAnalysisAI機能を、Google、Microsoft、Metaといった大手企業が公開している複数のオープンソースLLMモデルでベンチマークテストを実施しました。
当社のツールは英語だけでなく、多言語でのモデル評価に対応しており、特に日本語への特化が特徴です。この多言語評価により、グローバルなアプリケーションにおいて、より実用的なベンチマーク結果を提供しています。
Flow Benchmark Toolsは、実際のシナリオを反映するよう、日本政府が公表しているあらゆる文書と、難易度の高い質問を含む日本の政府文書のデータセットを使用しています。GPT-4、Claude 3、Geminiなど、最先端のモデルを複数活用し、0(最低)から10(最高)までの値を持つ平均意見評価を出力します。
詳細については、当社の発表記事をご覧ください。
Flow Benchmark Toolsは、GitHubおよびPyPiで公開されています。
オープンソースのLLMモデルは、サイズによってパフォーマンスが大きく異なるため、モデルサイズごとに評価することが重要です。大規模、中規模、小規模のモデル間では性能に大きな差があり、特に複雑なタスクにおいては大規模モデルが優れた精度を発揮します。一方で中・小規模モデルはコスト効率に優れ、低いハードウェア要件の個人用コンピュータでも実行可能です。
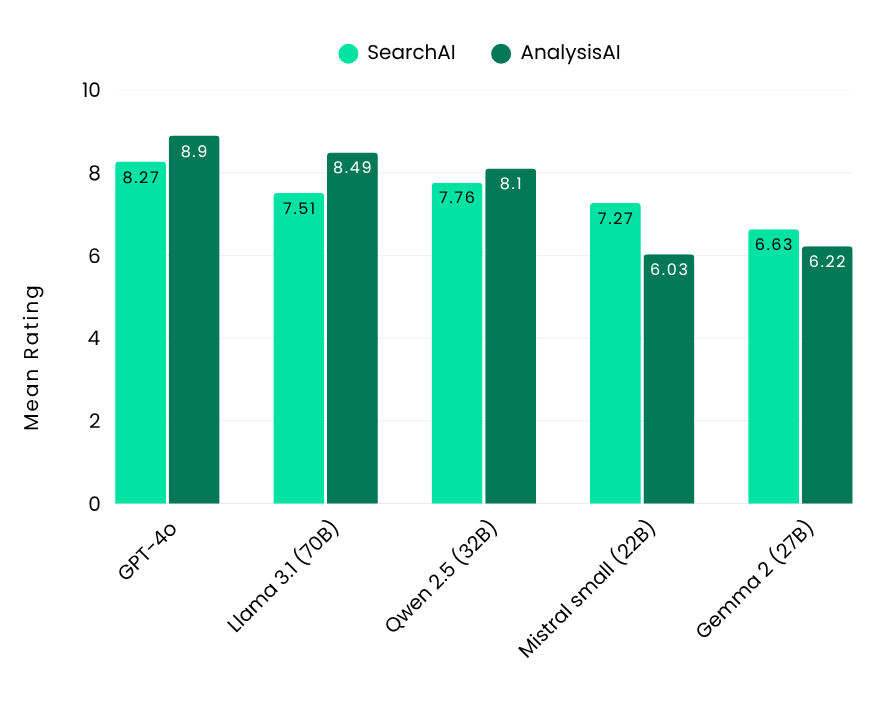
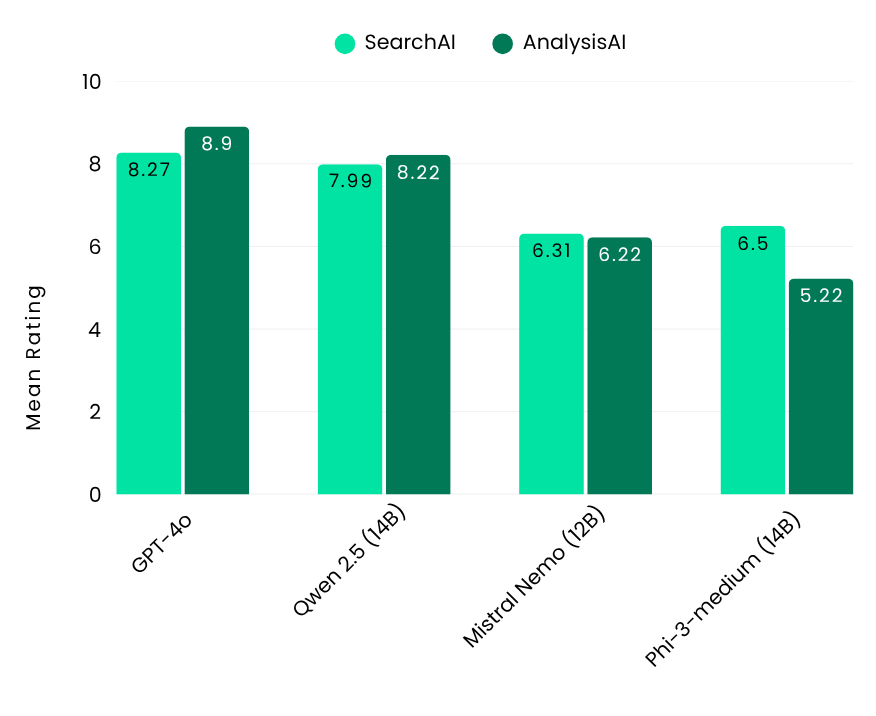
性能のベンチマークとして、業界トップレベルのGPT-4oを基準に評価した結果、SearchAIで8.27、AnalysisAIで8.9という高スコアを達成しました。
.png)
Flow Benchmarkの結果は、3つのサイズカテゴリーにおけるオープンソースLLMモデルのトップパフォーマーを示しました。大規模モデルでは、Llama 3.1-70B(Meta)とQwen 2.5-32B(Alibaba)がSearchAIとAnalysisAIの両方で優れた性能を発揮しました。中規模モデルでは、Qwen 2.5-14B(Alibaba)が特に多言語対応の強みを発揮し、英語と日本語の両方で優れた結果を示しました。小規模モデルの中では、GLM4-9B(Zhipu AI)が精度と効率で大規模モデルを上回り、印象的な成果を上げました。
今回の評価結果では、オープンソースLLMは、クローズドソースモデルと同等の性能を発揮できることを明確にしました。当社のFindFlowのようなプラットフォームを活用することで、企業は柔軟かつコスト効率の高いAIソリューションを構築できるようになります。
FindFlowがどのようにして貴社の業務を月に20時間以上節約し、最適なプラットフォーム選びをサポートできるかを詳しく知りたい方は、sbdm@recursiveai.co.jpまでお問い合わせください。
Google DeepMindの元シニアリサーチエンジニアによって設立されたRecursiveは、各分野で世界レベルの人材を集め、成果へと繋げています。






