
If you’re reading this blog post, you’re likely already familiar with Large Language Models (LLMs). You might also have heard of Retrieval-Augmented Generation (RAG), a technique that enables LLMs to access documents and databases, analyze information, and respond to user queries with references to specified documents.
RAG-powered models work great—if all you need to analyze is text. But what happens when your files contain pictures, graphs, diagrams, videos, or any other formats packed with valuable information beyond text? This is where Multimodal RAG comes into play. It takes information retrieval to an entirely new level, empowering enterprises to efficiently manage and analyze thousands of files, retrieving important information in seconds.
In this post, we’ll dive into what exactly Multimodal RAG is, explore the different approaches to building it, and share how Recursive developed a Multimodal-RAG-based system that can (and will) revolutionize learning experiences—from classrooms to corporate onboarding. True to our style, we won’t make empty promises or rely on buzzwords; the evaluation test results speak for themselves.
Multimodal Retrieval-Augmented Generation (RAG) is an advanced AI framework designed to retrieve and analyze information from multiple data formats (modalities). While traditional RAG focuses solely on text, Multimodal RAG extends this capability to include images, videos, charts, and other non-textual formats.
Enterprise data is rarely limited to plain text. Consider thousands of files stored in organizations—from PDFs containing charts and tables to instructional videos and images. Traditional text-based systems struggle to process and retrieve insights from such multimodal content. Multimodal RAG bridges this gap by:
There are several main approaches to building multimodal RAG pipelines. To keep this blog post concise, we will only discuss images and text input.
This approach involves using models like CLIP, which can encode text and images into a shared vector space. By doing so, the system can directly compare the semantic similarity between different modalities.
In this approach, all modalities are grounded into a primary modality, typically text. Non-text media, such as images, are described using text annotations, making them searchable as part of a unified text-based index.
This method involves maintaining separate stores for each modality. Queries retrieve top-N results from all stores, and a multimodal re-ranker determines the most relevant chunks across modalities.
This approach involves using document recognition solutions like ColPali to process entire documents holistically, eliminating the need for intermediary steps like Optical Character Recognition (OCR).
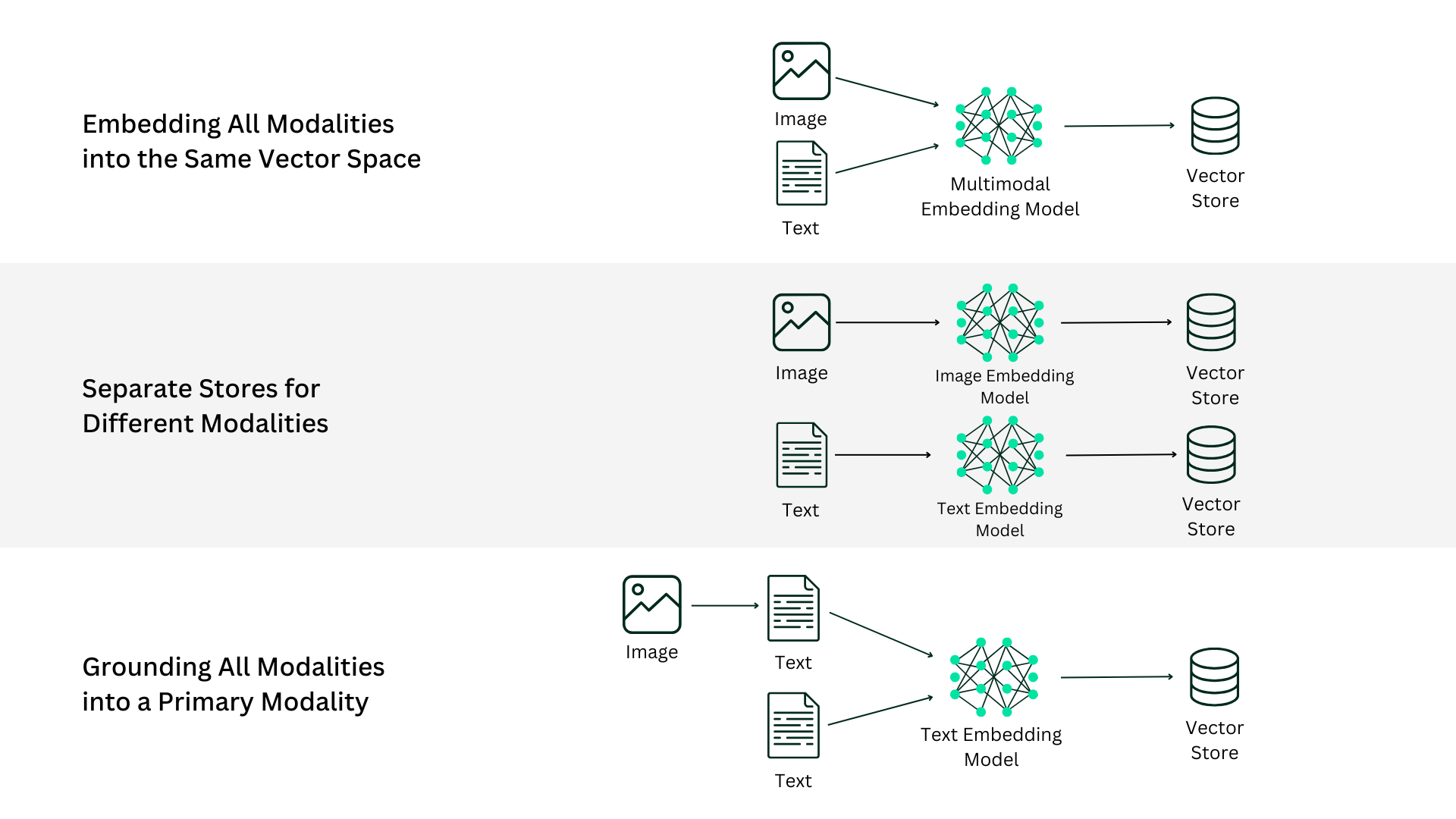
At Recursive, we adopted the approach of grounding all modalities into text for our Multimodal RAG system. This decision was driven by its simplicity and flexibility, enabling us to build a scalable pipeline while maintaining contextual relevance.
Our Multimodal RAG system is designed to transform how educational content is created, whether for professional training, academic learning, or corporate onboarding. It processes large amounts of multimodal documents (e.g., PDFs with text, images, and graphs) to automatically generate curriculums and interactive lesson materials, saving teachers and HR teams up to 90% of their time.
Below is a detailed breakdown of our Multimodal RAG implementation process.
.png)
Step 1: Extracting Images
We leveraged pre-trained document layout models to identify and extract images from source materials, such as PDFs. These models ensured accurate segmentation of visual elements while preserving their context within the document.
Step 2: Representing Images
To represent images in a searchable format, we generated descriptions using large language models (LLMs). Each description captures the semantic essence of the image that can be indexed and queried.
Step 3: Retrieving Images
Images were indexed alongside their captions and metadata (e.g., page number, document title). When building a lesson, the system queries the search index using text descriptions of the content, retrieving images that best match the context.
Step 4: Placing Images
An LLM is tasked with determining where to place retrieved images within the lesson. The placement decision is guided by contextual cues, such as the relevance of the image to specific sections or topics.
Step 5: Evaluating Placement
To ensure images are contextually relevant and effectively placed, we combine two evaluation metrics: cosine similarity and LLM-as-a-judge. Cosine similarity evaluates the semantic alignment between image descriptions and the surrounding section text. Meanwhile, the LLM-as-a-judge approach involves an LLM analyzing the relevance and educational value of image placements, assigning a score from 0 (completely irrelevant or misleading) to 10 (perfect placement, highly relevant, and enhances learning).
Using our Multimodal RAG system, we generated four courses with embedded images: History of Japan, Recursive Onboarding, Technical Maintenance Manual, and Transformers (the standard architecture for building large language models). For a baseline comparison, we used the original PDF documents with images placed by human judgment, as these placements can be considered optimal.
After assigning scores to the generated courses, we calculated the success rate as the percentage of placed images with scores of 7 or higher. The system achieved an impressive 81% success rate across the four courses. A detailed breakdown of the test results is provided in the table below.
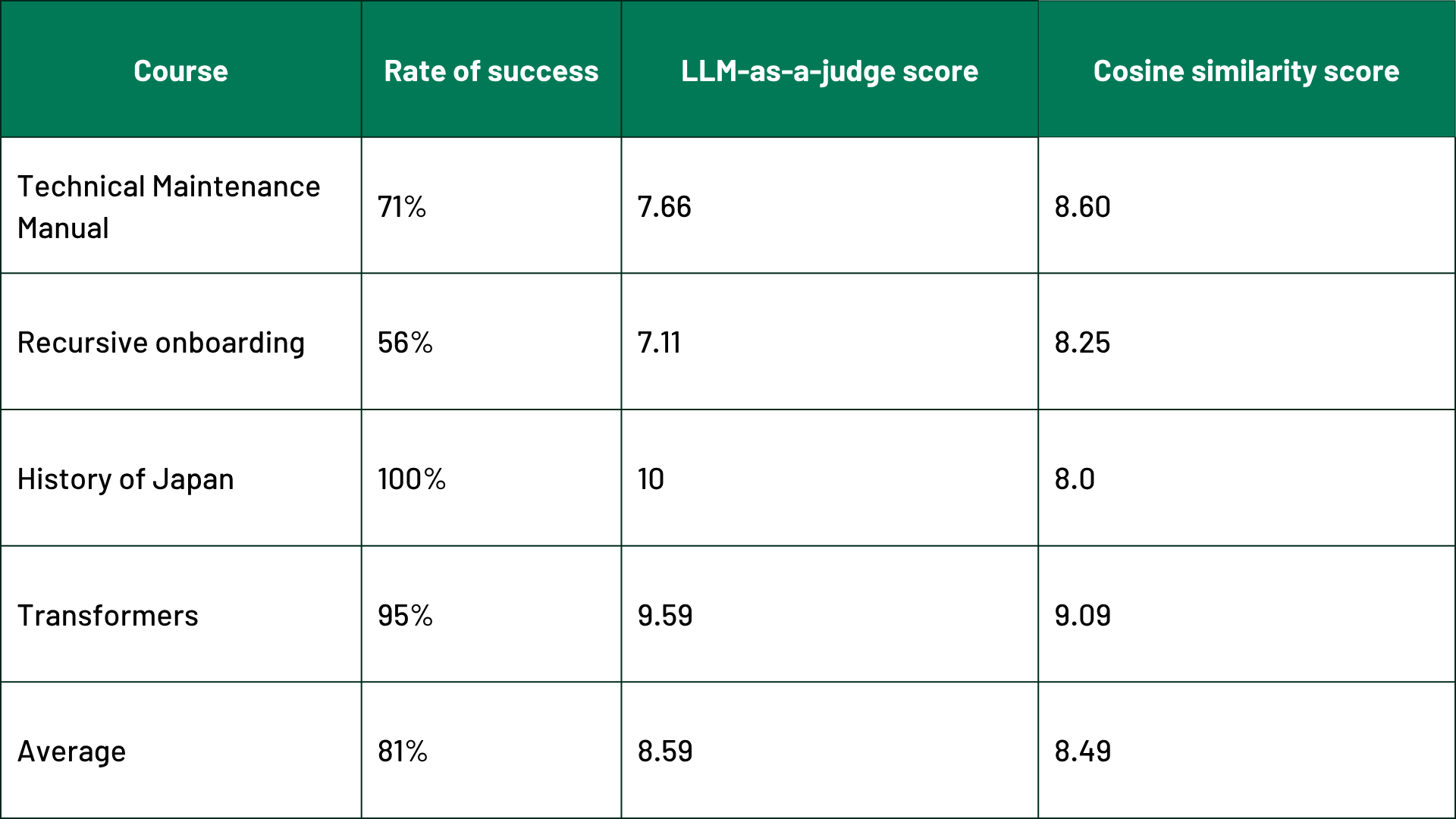
Although image placement is a highly subjective task, our evaluation metrics—cosine similarity and LLM-as-a-judge—provided clear, quantitative insights into placement quality. The high scores demonstrated that by grounding modalities into text, we successfully developed a robust pipeline that simplifies multimodal content generation.
This technological advancement is a significant step toward transforming teaching practices. By enabling the development of curriculums and multimedia educational materials in seconds, our Multimodal RAG system has the potential to save teachers, coaches, and HR teams up to 90% of their time.
Looking ahead, we are working to further improve image placement accuracy and expand the platform’s capabilities to include additional modalities like video and audio. If you’re interested in learning how this system can benefit your organization, please contact us at sbdm@recursiveai.co.jp.
Founded by a former senior research engineer at Google DeepMind, Recursive brings together world-class talent from across disciplines to engineer results where others can't.






