.png)
この記事を読んでいる方は、おそらく大規模言語モデル(LLM)については、既にご存知でしょう。さらに、検索拡張生成((Retrieval-Augmented Generation, 以下RAG)という技術についても耳にしたことがあるかもしれません。RAGは、LLMが文書やデータベースにアクセスし、情報を分析し、指定された資料を参照しながらユーザーの質問に答えることを可能にする技術です。
分析対象がテクストのみであれば、RAGを活用したモデルは非常に有効です。しかし、ファイル内に画像、グラフ、図、動画など、テクスト以外の情報が含まれている場合はどうでしょう?
マルチモーダルRAGは、まさにこの課題を解決するために登場しました。情報検索を全く新しいレベルに引き上げ、企業が数千ものファイルを効率的に管理・分析し、重要な情報を数秒で取り出すことを可能にします。
この記事では、マルチモーダルRAGがどんなものか、そして構築方法における様々なアプローチを検討します。さらに、Recursiveが開発した、教育現場から企業研修まで、学習体験を大きく変える可能性を秘めたマルチモーダルRAGを使ったシステムもご紹介します。口だけの約束や流行に流されることなく、実際の評価システムの結果に基づいてその効果を検証していきます。
マルチモーダルRAGは異なるデータ形式(モダリティ)からデータを検索・分析するように設計された、高度なAIフレームワークです。従来のRAGはテクストのみに特化していましたが、マルチモーダルRAGはこの機能を拡張し、画像、動画、グラフ、などの非テクスト形式にも対応します。
企業が有するデータは、テクストだけではありません。PDFに埋め込まれたグラフや表、動画や画像など、様々な形式で保存されています。従来のテクストベースの検索システムでは、このようなマルチモーダルコンテンツから有益な情報を引き出すことが困難でした。マルチモーダルRAGは以下の方法でこのギャップを埋めます。
マルチモーダルRAGパイプラインの構築には、いくつか主要なアプローチが存在しますが、ここでは、画像とテクスト入力を例に挙げ、主要な方法について解説します。
.png)
Recursiveでは、マルチモーダルRAGシステムにおいて、すべてのモダリティをテクストに変換するというアプローチを採用しました。この方法は、シンプルで柔軟性があり、文脈に応じた関連性を維持しながら、拡張可能なパイプラインを構築できるため選択されました。
当社のマルチモーダルRAGシステムは、FindFlowプラットフォーム上に構築されており、専門的なトレーニング、アカデミックな学習、企業のオンボーディングなど、教育コンテンツの作成方法を変革するように設計されています。大量のマルチモーダル文書(テクスト、画像、グラフなどを含むPDF)を処理し、カリキュラムやインタラクティブな教材を自動生成することで、教師やHRチームの作業時間を最大90%削減します。
以下は、RecursiveのマルチモーダルRAGの実装プロセスの詳細です。
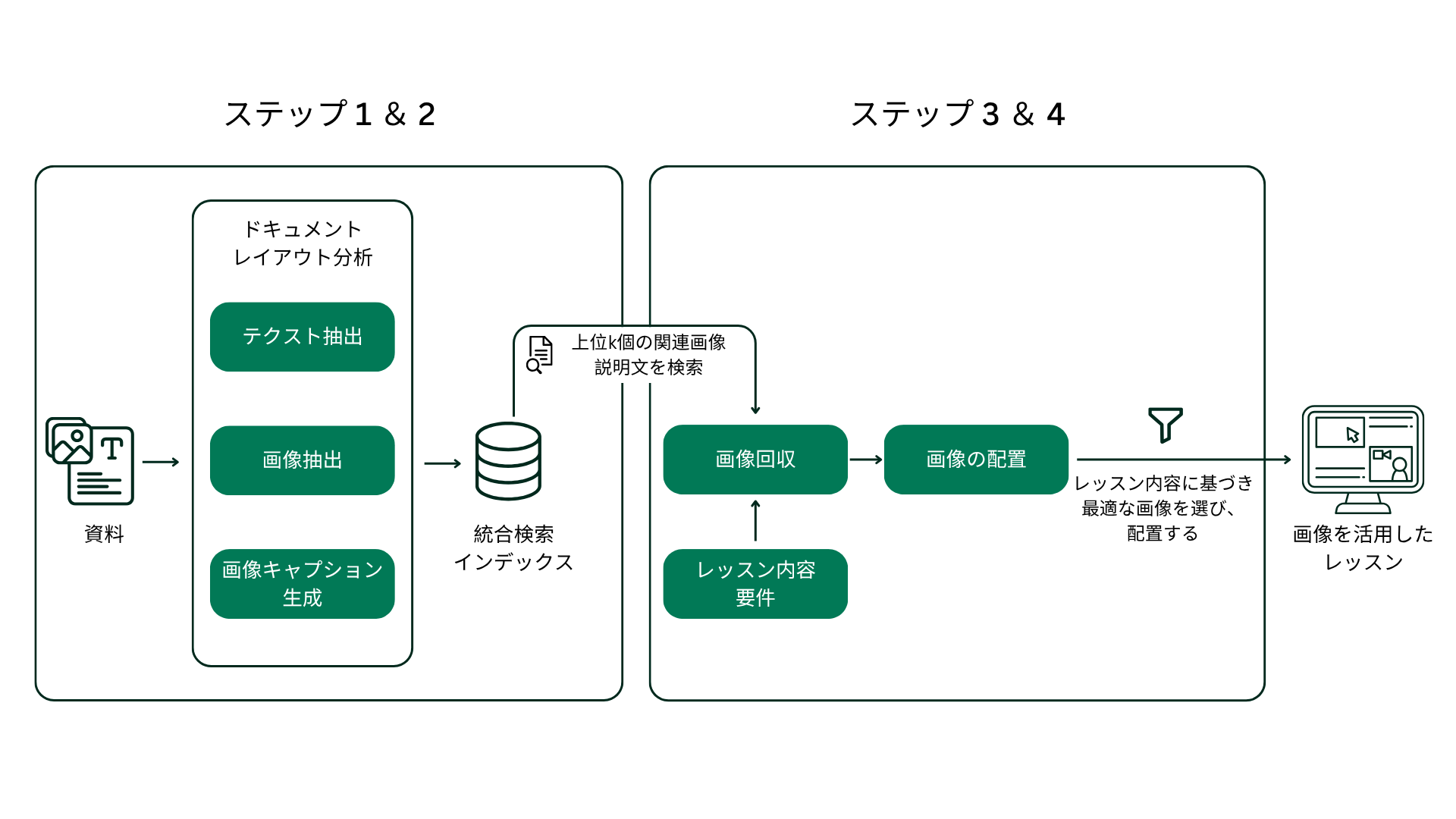
ステップ1:画像の抽出
PDFなどの資料から画像を特定し抽出するため、事前学習済みのドキュメントレイアウトモデルを活用しました。このモデルにより、ドキュメント内での文脈を維持しながら、ビジュアル要素を正確に分割することができました。
ステップ2:画像の表現
検索可能な形式で画像を表現するため、大規模言語モデル(LLM)を活用して説明文を生成しました。各説明文は、インデックス化およびクエリ可能な画像の意味的な本質を捉えています。
ステップ3:画像の検索
画像はキャプションやメタデータ(ページ番号、ドキュメントタイトルなど)とともにインデックス化されました。レッスンを作成する際、システムがコンテンツのテクスト記述を使用して検索インデックスにクエリを実行し、文脈に最も一致する画像を取得します。
ステップ4:画像の配置
取得した画像をレッスン内のどこに配置するかを決定するタスクは、LLMに委ねられます。配置の決定は、画像と特定のセクションまたはトピックとの関連性など、文脈的な手がかりによって導かれます。
ステップ5:配置の評価
画像が文脈的に関連性があり、効果的に配置されていることを保証するために、コサイン類似度(cosine similarity)とLLM-as-a-judgeといの2つの評価指標を組み合わせます。コサイン類似度は、画像の説明文と周囲のセクションテクストとの意味的な一致を評価します。一方、LLM-as-a-judgeのアプローチは、LLMが画像の配置の関連性と教育的価値を分析し、0(完全に不適切または誤解を招く)から10(完璧な配置、学習効果を最大化)までのスコアを割り当てます。
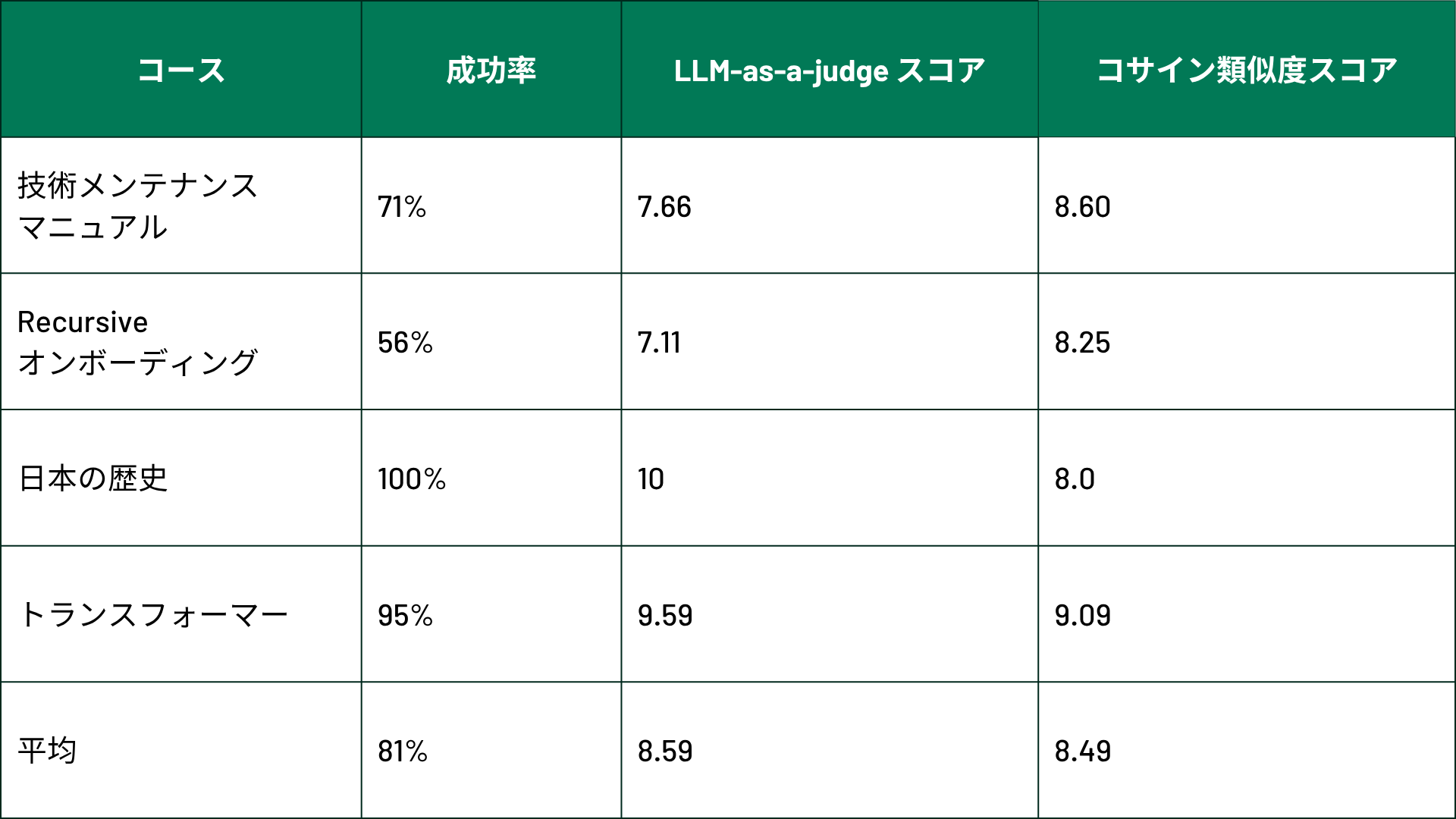
当社のマルチモーダルRAGシステムを活用し、画像が埋め込まれた4つのコース(「日本の歴史」、「Recursiveオンボーディング」、「技術メンテナンスマニュアル」、「トランスフォーマー(大規模言語モデル構築の標準アーキテクチャ」)を生成しました。比較対象としては、人間が最適な配置だと判断した画像を含むオリジナルのPDFドキュメントを使用しました。
生成されたコースにスコアを割り当てた後、7点以上のスコアを獲得した配置済みの画像の割合を成功率として算出しました。その結果、本システムは4つのコース全体で驚異的な81%の成功率を達成しました。テスト結果の詳細な内訳は以下の表に記載されています。
画像の配置は非常に主観的な要素を含むタスクです。しかし、私たちの評価指標であるコサイン類似度とLLM-as-a-judgeは、配置に関する明確かつ定量的な洞察を提供してくれました。高いスコアを獲得できたことは、様々な種類のデータ(モダリティ)をテクストに変換することで、マルチモーダルコンテンツ生成を簡素化する信頼性の高いパイプラインを開発できたことを示しています。
この技術的進歩は、教育現場に変革をもたらす大きな一歩です。当社のマルチモーダルRAGシステムは、カリキュラム作成やマルチメディア教育・研修のあり方を一変させる画期的なソリューションです。カリキュラムやマルチメディア教育資料の作成時間を大幅に短縮し、教師、研修担当者、人事担当者の業務効率を最大90%削減する可能性があります。
今後は、画像配置の精度をさらに向上させるとともに、動画や音声などの追加モダリティへの対応も進めていきます。本システムが貴社の業務にどのように役立つかご興味のある方は、ぜひsbdm@recursiveai.co.jpまでお問い合わせください。
Google DeepMindの元シニアリサーチエンジニアによって設立されたRecursiveは、各分野で世界レベルの人材を集め、成果へと繋げています。






