.png)
ChatGPTが2022年11月にリリースされて以来、テクノロジー大手企業はより大規模で高度な大規模言語モデル(LLM)の開発競争を繰り広げてきました。この競争は激化しており、新しいモデルが登場しても業界が大きく揺れることは少なくなっています。しかし、DeepSeekの最新リリースは例外でした。 中国のAIスタートアップ企業であるDeepSeekは、通常と比べて圧倒的に低コストで、高度なパフォーマンスを実現する高性能な推論モデルR1を発表したのです。
DeepSeekは当初、モデルのトレーニングコストがわずか600万ドルだったと発表しました。これはOpenAIやGoogleなどのAI大手が通常費やす費用と比べて桁違いに小さいものでしたが、後に、この数字は最終的なトレーニングランのみのコストであり、実際には複数回のトレーニングプロセスが必要であることが明らかになりました。
それにも関わらずこの発表はAI関連株の急落を引き起こし、Nvidiaの時価総額は上場企業の一日当たりの減少額としては過去最大の6000億ドル近くも減少しました。ただし市場は急速に回復し、Nvidiaは24時間以内に損失の約半分を取り戻しました。
金融市場の動向はさておき、本記事ではDeepSeek-R1がなぜこれほど注目されるのか、そして、オープンソースモデルがAIのパフォーマンス、ハードウェア要件、コスト構造の進化をどのように加速させるのかについて解説します。
DeepSeek-R1が話題となっている主な理由は技術革新とオープンソース化の2つです。OpenAIなどの企業がモデルのトレーニングプロセスを非公開にしているのに対し、DeepSeekはコードやトレーニングデータを公開しており、研究者や小規模な企業が数十億ドル規模の投資なしに最先端技術を活用できるようにしています。
では、DeepSeek-R1はどのような技術によってOpenAIの最先端モデルに匹敵する性能を発揮しているのでしょうか?
従来のLLMはすべてのクエリを一定の計算量を使用する静的推論により処理します。例えば、「日本の首都はどこ?」というシンプルな質問と、「気候変動の経済的影響を説明してください」という複雑な推論が必要な質問、どちらに対しても同じ計算量を消費する仕組みです。この固定的なアプローチは単純なタスクには適していますが、高度な分析が求められる課題には不向きです。
テスト時計算(TTC)はこの問題を解決し、タスクの複雑さに応じて計算リソースを動的に割り当てることを可能にします。そして 簡単な質問には最小限の処理で素早く回答し、複雑な問題には「一時停止して考える」ことにより、追加のリソースを活用しながら計算を繰り返し推論を深めるステップを繰り返すことで回答を洗練させ最適な最終回答を生成します。
この仕組みは人間の思考プロセスに似ています。我々が、簡単な質問には即座に答えられる一方で、複雑な問題は時間をかけて考え、情報を分析し、論理的に整理したうえで答えを導き出すのと同様なのです。
このプロセスの鍵となるのが*リワードモデリング(Reward Modeling)*です。リワードモデリングでは、複数の回答候補を生成し、それぞれを正確性、一貫性、論理的整合性に基づいてスコア化することによって最終的に最もスコアの高い適切な回答を選択します。 この手法により、より適切かつ論理的で、意図した目的に沿った回答を提供できるようになるのです。
OpenAIのo1やGoogleのGemini 2.0 Flash ThinkingもTTCを取り入れていますが、DeepSeek-R1はTTCを実装した初のオープンソースモデルであり、高度な推論機能を世界中の研究者や開発者に利用可能としました。

DeepSeekモデルの、計算コストを削減し効率性を向上させるもう一つの重要な技術が混合専門家モデル (Mixture of Experts, MoE) アーキテクチャです。MoE自体は新しい技術ではなく、すでにDeepSeekの前モデルV3に採用されており、他のオープンソースモデルでも導入されています。2023年にはフランスのAI企業MistralがMoEベースのオープンソースモデルMixtral 8x7BとMixtral 8x22Bを発表したように、このアプローチを採用する動きは加速しています。
では、MoEはどのように機能するのでしょうか?従来のLLMは何千億ものパラメータを持ち、トークンを生成する際、実際にはネットワークの一部しか必要でない場合でもすべてのクエリに対してモデル全体を起動させるため非常に多くの計算リソースを消費します。この為、計算資源が過剰に消費され、大規模モデルの運用コストが高くなり、小型デバイスへの導入が困難になっていました。
MoEはこの非効率性を解決するためにモデルを複数の「専門家」サブネットワークに分割し、入力トークンごとに最適な専門家のみを動作させます。ゲーティングネットワークが動的に適切な専門家を選択することで計算資源の無駄を削減します。どのクエリにもDeepSeekの6710億のパラメータすべてを使用するのではなく、MoEはタスクに応じてごく一部の約370億パラメータのみを選択して処理を行うのです。
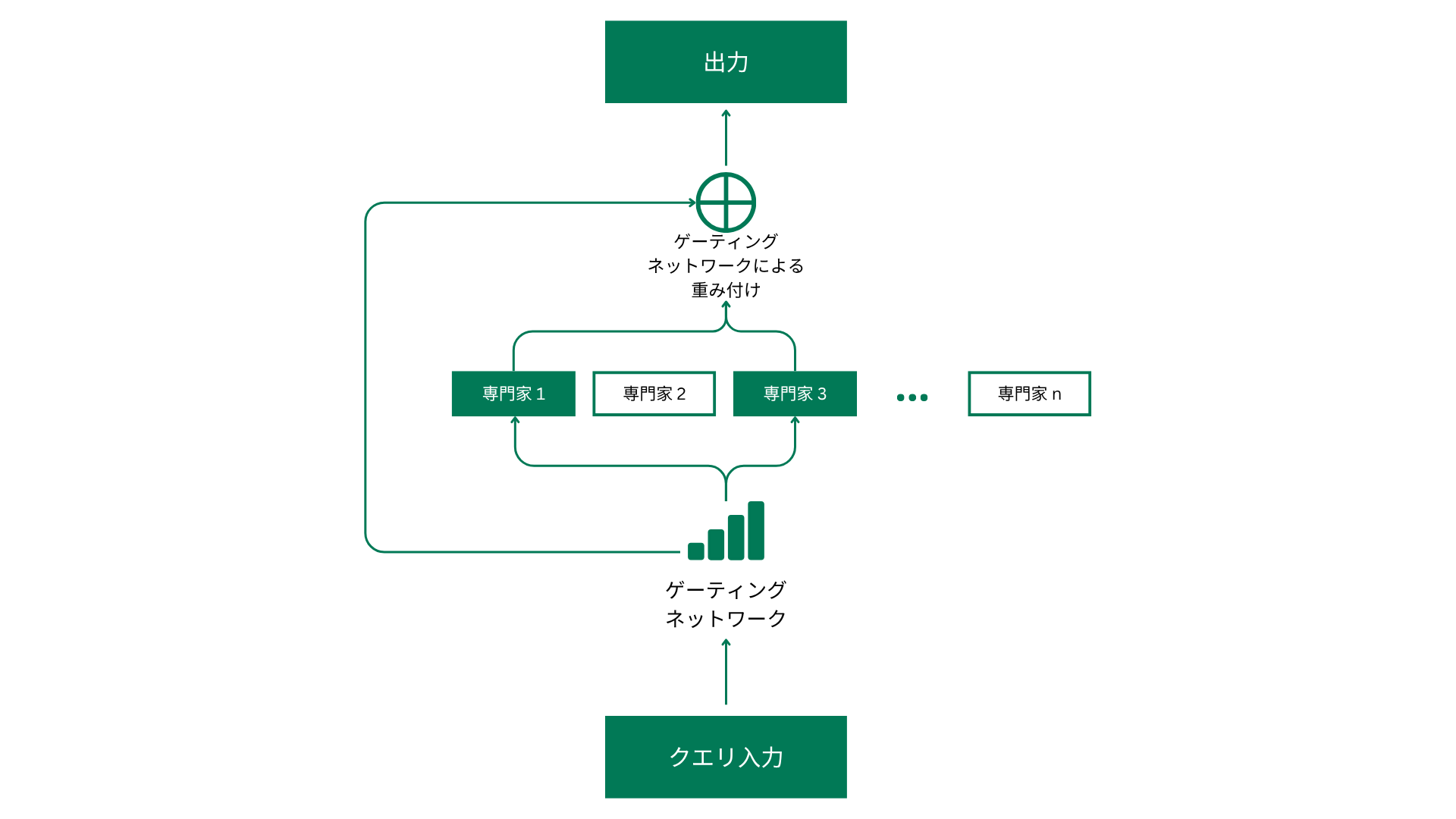
このアプローチは計算コストとGPUリソースの消費を大幅に削減できるため、モデルの運用コストを下げ、より小型のデバイスでも動作可能とします。自宅のパソコンでChatGPT-4oに匹敵する性能を持つモデルを動作させ、更にそのコードやトレーニングデータにフルアクセスできると、しかも、それがChatGPT-4oよりも4.5倍安いコストでできると想像してみてください。
このようなアクセシビリティの高さこそがDeepSeekのモデルの強みなのです。これにより、スタートアップ企業や個人の研究者でも大規模なインフラ投資を必要とせずに、モデルをファインチューニングすることで強力なAIソリューションを開発することができるのです。
これらの技術は組み合わせることで高性能かつ低コストを実現できますが、決して新しいものではありません。オープンソースエコシステムの最大の利点は、新しいモデルが世界中のエンジニアによって研究・改良・ファインチューニングされ、継続的な進化につながることにあります。このイノベーションのサイクルにより近年オープンソースLLMは飛躍的に進化し、よりスマートで、高速で、より小型のデバイス上でも動作可能となってきたのです。
最新記事「最優秀オープンソースLLMモデル」や「小規模言語モデルのファインチューニング:少ないリソースでのパフォーマンス向上」もぜひご覧ください。
あと1ヶ月もすれば、MetaやGoogleなどの企業が同等かそれ以上のオープンソースモデルをリリースする可能性は十分にあります。それでもDeepSeekがこれほどまでに大きな衝撃を与えたのは、その技術的な成果だけでなく、シリコンバレーから遠く離れた場所、それも2022年以降アメリカの規制によりAIチップの輸出が制限されている中国で開発されたことにあります。
まとめると、DeepSeek-R1の登場はAIの進化において以下の2つの重要なトレンドを示しています。
Meta、Google、Alibabaなどの企業は、ファインチューニングすることでより高い性能を発揮することができる30億パラメータの小型オープンソースモデルをすでに公開しており、高性能なLLMをスマートフォンで動作させることができる未来は確実にやってきます。
2. オープンソース技術への移行は、より迅速で低コストかつ透明性の高いAI開発を可能とする
これにより、一部の大手企業による独占状態を打破し、より多くのプレイヤーがAI開発とイノベーションに参加できるようになります。この流れは、世界中の知識をよりアクセスしやすくすることでAIをサステナビリティに活用するというRecursiveのミッションとも一致しています。オープンソースのエコシステムにより、異なる言語や文化の独自性を考慮してLLMをファインチューニングすることが可能となり、より幅広い層にAIを提供することができるようになるのです。
Recursiveは、オープンソースAIの発展を支援し、最新の研究や技術革新を活用して産業の持続可能な成長を促進するAIソリューションを提供しています。これらのソリューションが貴社のビジネスにどのように役立つかご興味がありましたらぜひ当社までお問い合わせください。
Google DeepMindの元シニアリサーチエンジニアによって設立されたRecursiveは、各分野で世界レベルの人材を集め、成果へと繋げています。






